Abstract
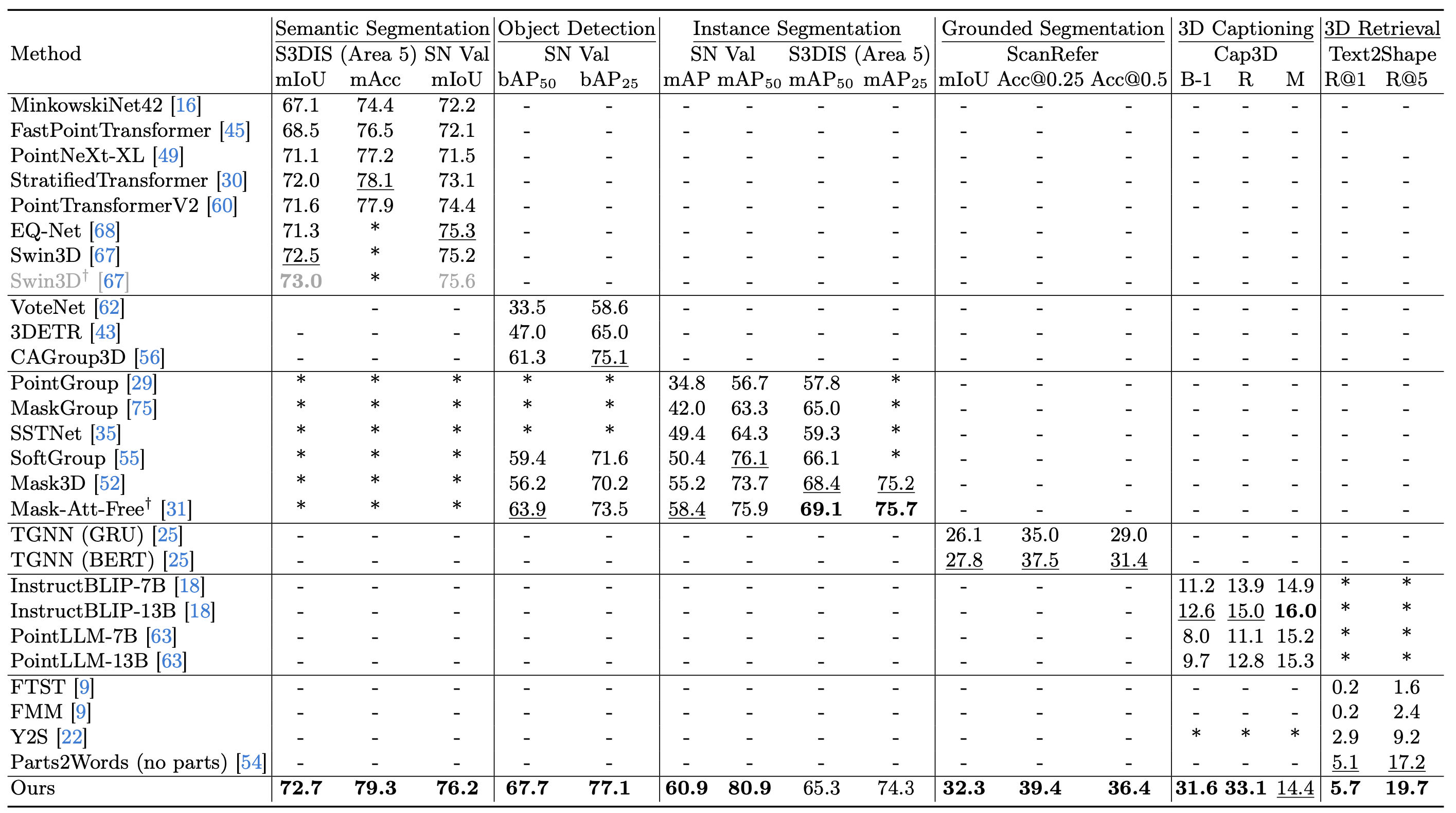
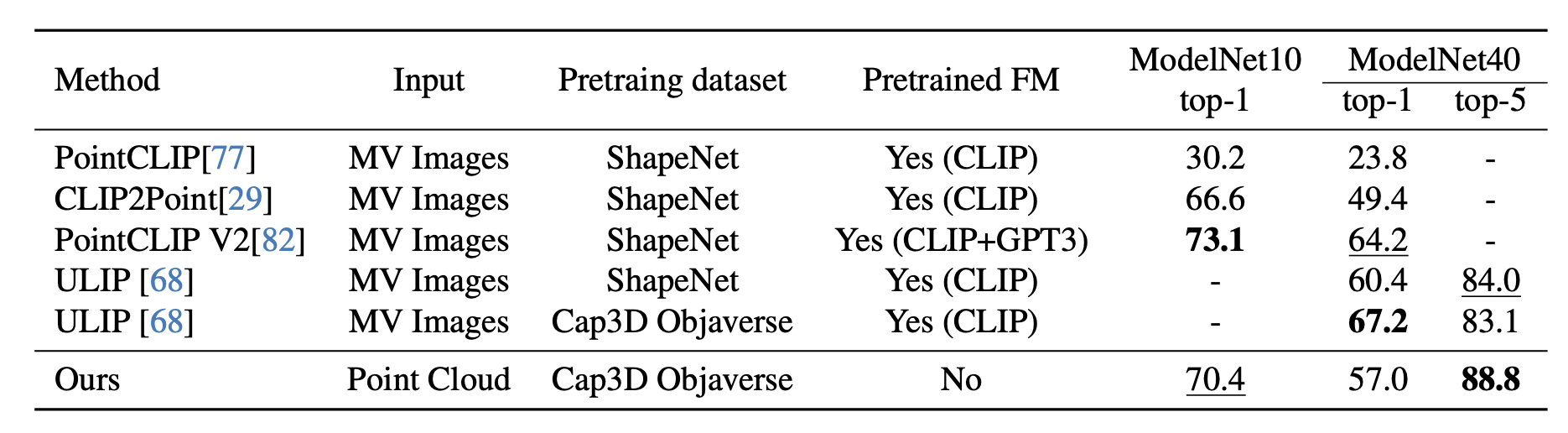
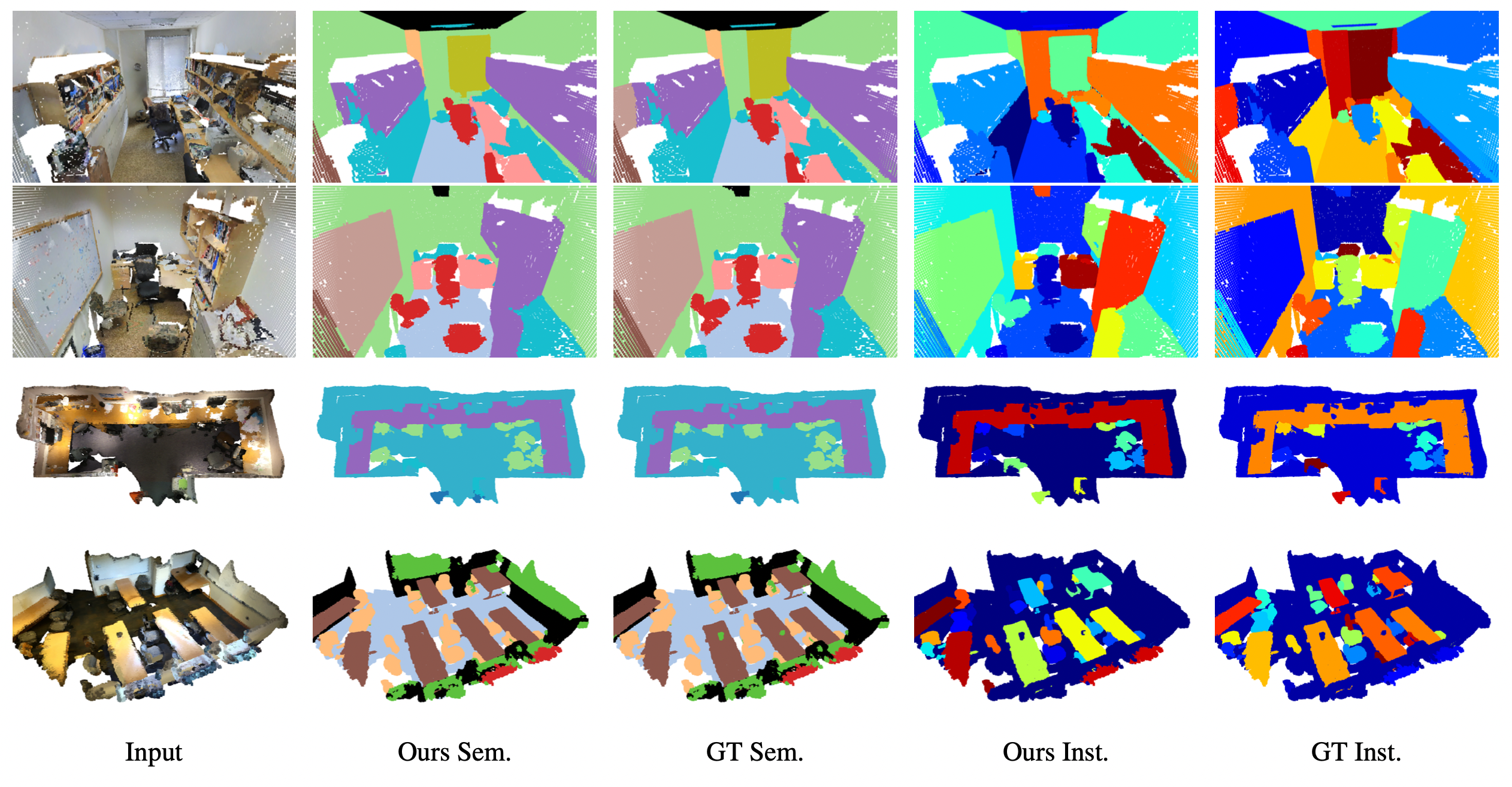
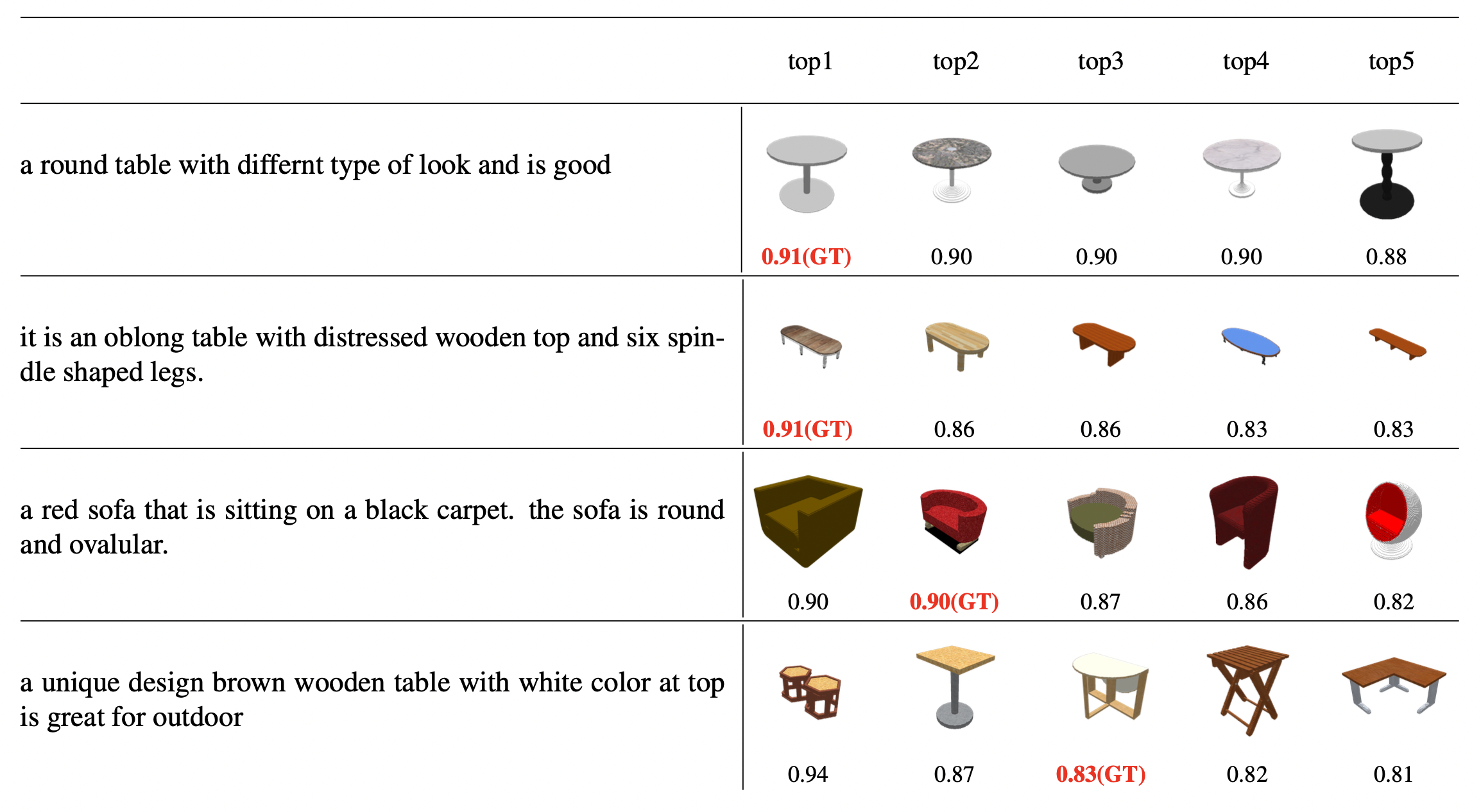
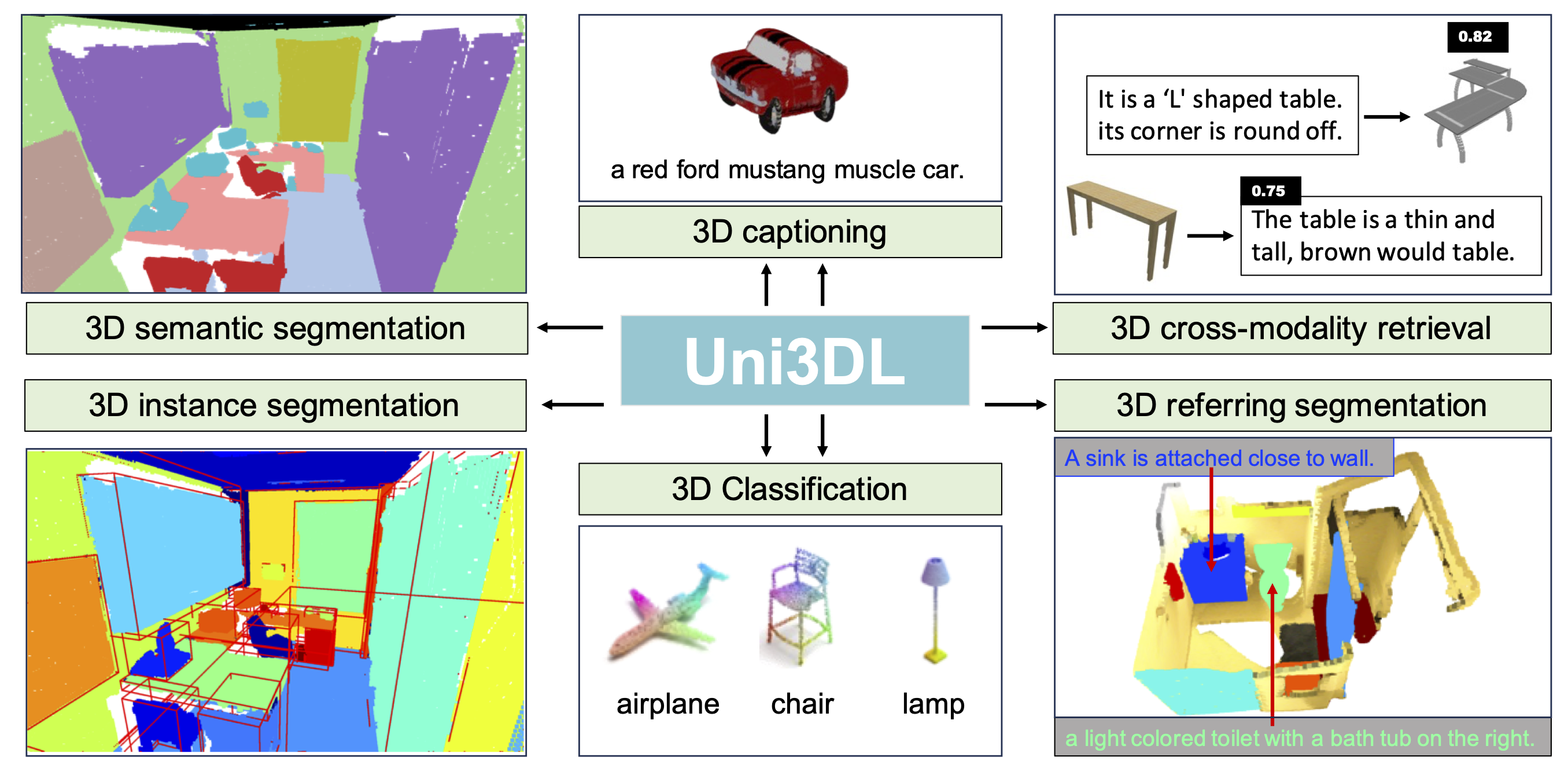
We present Uni3DL, a unified model for 3D and Language understanding. Distinct from existing unified vision-language models in 3D which are limited in task variety and predominantly dependent on projected multi-view images, Uni3DL operates directly on point clouds. This approach significantly expands the range of supported tasks in 3D, encompassing both vision and vision-language tasks in 3D. At the core of Uni3DL, a query transformer is designed to learn task-agnostic semantic and mask outputs by attending to 3D visual features, and a task router is employed to selectively generate task-specific outputs required for diverse tasks. With a unified architecture, our Uni3DL model enjoys seamless task decomposition and substantial parameter sharing across tasks. Uni3DL has been rigorously evaluated across diverse 3D vision-language understanding tasks, including semantic segmentation, object detection, instance segmentation, visual grounding, 3D captioning, and text-3D cross-modal retrieval. It demonstrates performance on par with or surpassing state-of-the-art (SOTA) task-specific models. We hope our benchmark and Uni3DL model will serve as a solid step to ease future research in unified models in the realm of 3D and language understanding.
Model
The Uni3DL is engineered for multifaceted 3D data tasks, including classification, retrieval, captioning, semantic and instance segmentation, as well as visual grounding. The architecture is composed of four principal modules: ① a Text Encoder for textual feature extraction; ② a Point Encoder for point feature learning; ③ a Query Transformer Module, which is the cornerstone of the system with a sequence of cross-attention and self-attention operations between latent queries, text queries and voxel features derived from the Point Encoder; and ④ a Task Router module, which comprises, as needed for the given task, text generation head for generating descriptive text, a grounding head for text-to-object grounding, a class head for object classification task, a mask head dedicated to segmentation, and a text-3D matching head for 3D-text cross modal matching. The text generation head functions in an autoregressive manner and predicts one token at each forward step.

Figure 1. Method overview of Uni3DL.